점근적 실행시간, 또는 big-O 시간에 대한 개념 이라고 말을 합니다. 예를 들어 데이터 전송 '알고리즘'의 실행시간을 예를 들어 보겠습니다.
온라인 전송 : O(s). 여기서 s는 파일의 크기가 된다. 즉, 파일의 크기가 증대함에 따라 전송 시간 또한 선형적으로 증가합니다.
비행기를 통한 전송 : O(1). 파일 크기에 관계없이 파일을 전송하는데 걸리는 시간이 늘어나지 않는다. 즉, 상수 시간만큼 소요된다.
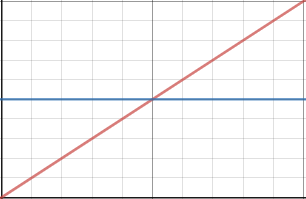
간단하게 그래프로 그려 보겠습니다.
파랑 : O(1), 빨강 : O(s)
시간복잡도를 구할 때 기억할 것
상수항은 무시하라
지배적이지 않은 항은 무시하라
상수항은 무시하라
만든 알고리즘의 시간 복잡도가 4N+100000라는 시간이 걸린다고 생각해보자. N값의 따라 걸리는 시간이 달라진다. N의 값이 점점 커지고 여러분이 상상하는 가장 큰 숫자가 된다고 생각해보자. 뒤에 상수항은 그 숫자에 얼마나 큰 영향을 주게 되나요?
지배적이지 않은 항은 무시하라
이번에 만든 알고리즘의 시간복잡도는 N2 + N + 1000000 의 시간이 걸린다고 생각해보자. 이번에도 N의 값을 계속해서 키워나갈 때, N2의 값, N의 값, 1000000 들의 변화를 살펴보자. N2값에 비하면 N은 상수항과 비슷한 느낌을 받는다. 즉, N2값에 따라 이 알고리즘이 걸리는 시간이 결정된다. 그러므로 이 알고리즘을 big-O표기법을 사용해 표현하면 O(n2)의 시간복잡도를 가진다고 말할 수 있다.
덧셈 vs 곱셈
덧셈 수행시간 : O(A + B)
1
2
3
4
5
6
7
for(int a : arrA) {
print(a);
}
for(int b : arrB) {
print(b);
}
곰셈 수행시간 (A * B)
1
2
3
4
5
for(int a : arrA) {
for(int b : arrB) {
print(a + "," + b);
}
}
알고리즘이 두 단계로 이루어져 있다고 가정하자. 어떤 경우에 수행 시간을 곱하고 어떤 경우에 더해야 할까?
만약 알고리즘이 "A 일을 모두 끝마친 후에 B일을 수행"하는 형태라면 A와 B의 수행시간을 더해야한다.
만약 알고리즘이 "A 일을 할 때마다 B일을 수행"하는 형태라면 A와 B의 수행시간을 곱해야 한다.
log N 수행시간
O(logN) 수행 시간을 자주 접할텐데 이 수행 시간은 어떻게 구해진걸까?
binary search(이진 탐색)을 생각해보자. 이진 탐색은 N개의 정렬된 원소가 들어있는 배열에서 원소 x를 찾을 때 사용된다. 먼저 원소 x와 배열의 중간값을 비교한다. 'x==중간값'을 만족하면 반환한다. 'x < 중간값'일 때는 배열의 왼쪽 부분을 재탐색하고 'x > 중간값'일 경우에는 배열의 오른쪽 부분을 재탐색한다.
처음에는 N개가 들어있는 배열에서 시작한다. 한 단계가 지나면 탐색해야할 원소의 개수가 N/2로 줄어들고, 다음 단계에서는 N/4로 줄어든다. 그러다 원소를 찾거나 탐색할 원소 1개가 남으면 탐색을 중지한다.
시작 N이 16이라고 가정하고 정리하면,
N = 16
N = 8
N = 4
N = 2
N = 1 의 결과로 원하는 x를 찾을 수 있다.
반대로 16에서 1로 증가하는 순서로 생각해보면 1에 2를 몇번이나 곱해야 할까?
N = 1
N = 2
N = 4
N = 8
N = 16 약, 4번 2를 곱하고 결과 값을 얻을 수 있다.
즉 2k = N을 만족하는 k는 무엇인가? 이때 사용되는 것이 바로 로그(log)이다.
2k = N ▶ log216 = 4 ▶ 4
log2N = k ▶ 2k = N
어떤 문제에서 원소의 개수가 절반씩 줄어든다면 그 문제의 수행 시간은 O(logN)이 될 가능성이 크다. 로그의 밑은 고려하지 않아도 된다. 밑이 다른 로그는 오직 상수항만큼만 차이가 나는데 위에서 언급했듯이 상수항은 영향이 크지 않다. 표현할 때도 logN으로 표현되며, 로그의 밑은 무시해도 된다.
재귀적으로 수행시간 구하기
1
2
3
4
5
6
int f(int n) {
if (n <= 1) {
return 1;
}
return f(n -1) + f(n - 1);
}
재귀 함수의 수행시간은 어떻게 구해야할까? 함수 f가 두 번 호출된 것을 보고 성급하게 O(N2)이라고 결론 내린 사람은 다시 생각해보자. 수행 시간을 추측하지 말고 코드를 하나씩 읽어 나가면서 수행 시간을 계산해 보자. n = 4라고 가정하자.
f(4)는 f(3)을 두번 호출한다.
f(4) : f(3), f(3)
f(3)은 f(2)를 두번 호출하며 f(3)은 2개가 있다.
f(3) : f(2), f(2) * 2
f(2)는 f(1)을 두번 호출하며 f(2)는 4개가 있다.
f(2) : f(1), f(1) * 4
총 호출 횟수는 몇 개인가? 일일이 세지 말고 계산해보자!
f(4)
f(3) f(3)
f(2) f(2) f(2) f(2)
f(1) (f1) f(1) f(1) f(1) f(1) f(1) f(1)
트리의 형태로 표현하면 위와 같다. 트리의 깊이가 N이고, 각 노드는 두개의 자식 노드를 갖고 있다. 따라서 깊이가 한 단계 깊어질 때마다 이전보다 두 배 더 많이 호출하게 된다. 같은 높이에 있는노드의 개수를 세어 보자.
깊이
노드의 개수
다른 표현방식
또 다른 표현방식
0
1
20
1
2
2 * 2이전 깊이 = 2
21
2
4
2 * 2이전 깊이 = 2 * 21=22
22
3
8
2 * 2이전 깊이= 2 * 22=23
23
따라서 전체 노드의 개수는 20 + 21 + 2 2 + ... + 2N(=2N+1-1)이 된다. 이 패턴을 기억하길 바란다. 다수의 호출로 이루어진 재귀 함수에서 수행시간은 보통 O(분기깊이)로 표현되곤 한다. 여기서 분기란 재귀 함수가 자신을 재호출하는 횟수를 뜻한다. 따라서 예제의 경우에 수행 시간은 O(2n)이 된다.
앞에서 언급했는데 로그의 밑은 상수항으로 취급되기 때문에 big-O표기법에서 로그의 밑은 무시해도 된다고 했었다. 하지만 지수에서는 얘기가 달라진다. 지수의 밑은 무시하면 안된다. 간단한 예로 2n과 8n을 비교해보자.
8n은 2(3)n = 23n = 22n*2n 으로 표현할 수 있다. 8n은 2n에 22n을 곱한 것과 같으므로 2n과 8n사이에는 22n만큼의 차이가 있다. 이 차이는 지수항이므로상수항과는 아주 큰 차이가 있다.
처음에는 big-O 시간이라는 개념이 어렵게 느껴질 수 있다. 하지만 한번 이해하면 꽤 쉽게 받아들일 수 있으니 다른 코드나 자신이 만든 코드의 시간 복잡도가 어떻게 되는지 위와 같이 계산해보길 바란다.
오메가 : 최선의 시간을 고려 세타 : 평균의 시간을 고려 오 : 최악의 시간을 고려 (세타를 O(오)로 통합해 표현하기도 합니다)